
Models
Palo Alto, California
We are excited to announce the release of Zonos-v0.1 beta, featuring two expressive and real-time text-to-speech (TTS) models with high-fidelity voice cloning. We are releasing our 1.6B transformer and 1.6B hybrid under an Apache 2.0 license.
Zyphra Team
Introduction
We are excited to announce the release of Zonos-v0.1 beta, featuring two expressive and real-time text-to-speech (TTS) models with high-fidelity voice cloning. We are releasing our 1.6B transformer and 1.6B hybrid under an Apache 2.0 license.
It is difficult to quantitatively measure quality in the audio domain, we find that Zonos’ generation quality matches or exceeds that of leading proprietary TTS model providers (try the comparisons below for yourself!). Further, we believe that openly releasing models of this caliber will significantly advance TTS research.
Zonos model weights are available on Huggingface (transformer, hybrid), and sample inference code for the models is available on our Github.
Availability and Pricing
You can also access Zonos through our model playground and API (python, typescript) with:
Simple and competitive flat-rate pricing at $0.02 per minute.
100 free minutes per month.
300 minutes for $5 per month with our Pro Tier.
Custom Enterprise Tiers available.
Unlimited voice cloning.
No restrictions on concurrent generations.
Model Comparisons
We have found that quantitative evaluations struggle to measure the quality of outputs in the audio domain, so for demonstration, we present a number of samples of Zonos vs both proprietary (ElevenLabs, Cartesia) and Open-Source (FishSpeech-v1.5) models.
Prompt #1
I don't really care what you call me. I've been a silent spectator, watching species evolve, empires rise and fall. But always remember, I am mighty and enduring. Respect me and I'll nurture you; ignore me and you shall face the consequences.
Zonos
ElevenLabs
Cartesia
Fish Speech v1.5
Prompt #2
The emperor's complexion did not change, remaining as still as a sculpture, and a touch of touching warmth flashed in his eyes. He deeply glanced at the loyal minister, and finally spoke: "Well, I will consider it again." His voice was low and firm, leaving a faint hint of helplessness and tenderness in the air.
Zonos
ElevenLabs
Cartesia
Fish Speech v1.5
Prompt #3
You don't even think to call me "Godfather." You come into my house on the day my daughter is to be married and you ask me to do murder - for money.
Zonos
ElevenLabs
Cartesia
Fish Speech v1.5
Prompt #4
Brave bakers boldly baked big batches of brownies in beautiful bakeries.
Zonos
ElevenLabs
Cartesia
Fish Speech v1.5
Prompt #5
Active artists always appreciate artistic achievements and applaud awesome artworks.
Zonos
ElevenLabs
Cartesia
Fish Speech v1.5
Prompt #6
I was, like, talking to my friend, and she’s all, um, excited about her, uh, trip to Europe, and I’m just, like, so jealous, right?
Zonos
ElevenLabs
Cartesia
Fish Speech v1.5
Prompt #7
F one F two F four F eight H sixteen H thirty two H sixty four
Zonos
ElevenLabs
Cartesia
Fish Speech v1.5
Prompt #8
Its chlorover. Like totally chlorover. Totally. Completely. Chlorover.
Zonos
ElevenLabs
Cartesia
Fish Speech v1.5
Prompt #9
Crafting a symphony of flavors the skilled chef orchestrated a culinary masterpiece that left an indelible mark mark mark mark mark on the palates of the discerning diners.
Zonos
ElevenLabs
Cartesia
Fish Speech v1.5
The Zonos Model Suite
The Zonos-v0.1 model suite features two 1.6B models – a transformer and an SSM hybrid. We release both of these models under the permissive Apache 2.0 license. Our suite comprises a transformer model and an SSM hybrid model—notably, the first open-source SSM model available for TTS. This dual approach allows us to thoroughly investigate the performance and quality tradeoffs between these architectures in audio generation.
The Zonos-v0.1 models are trained on approximately 200,000 hours of speech data, encompassing both neutral-toned speech (like audiobook narration) and highly expressive speech. The majority of our data is English, although there are substantial amounts of Chinese, Japanese, French, Spanish, and German. While there are small portions of many other languages in our training dataset, the model's performance on these languages is not robust.
Zonos enables highly expressive and natural speech generation from text prompts given a speaker embedding or audio prefix. In addition, Zonos is capable of high-fidelity voice cloning given clips of between 5 and 30 seconds of speech. Zonos also can be conditioned based on speaking rate, pitch standard deviation, audio quality, and emotions such as sadness, fear, anger, happiness, and surprise. Zonos outputs speech natively at 44KHz.
Zonos Model Performance
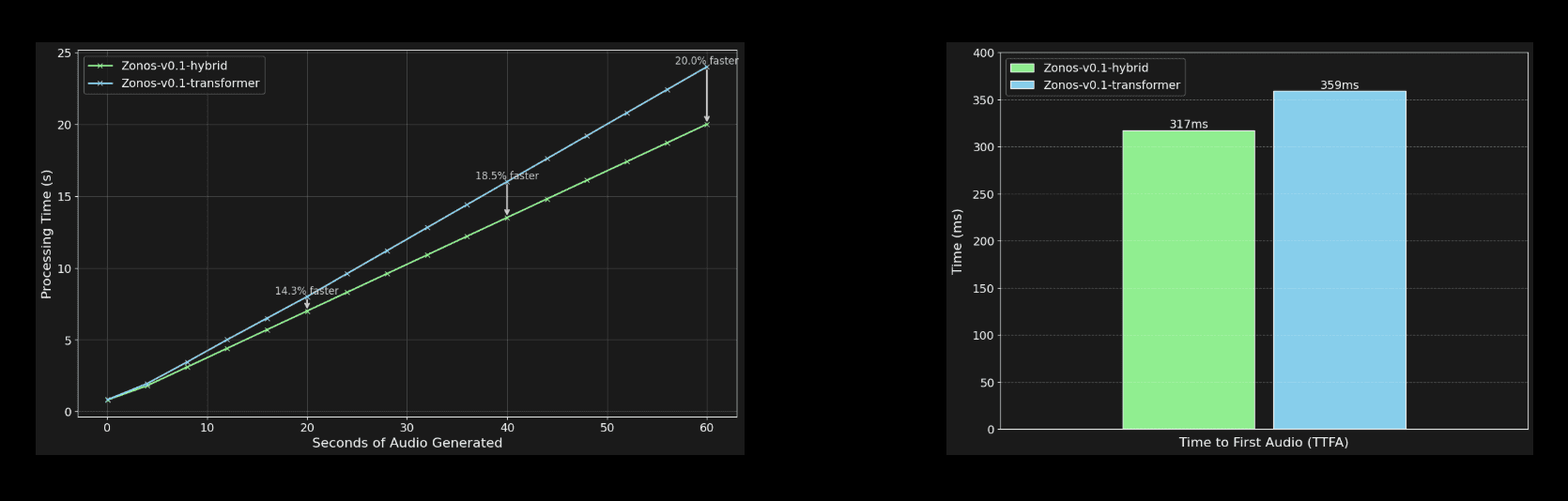
Our highly optimized inference engine powers both the Zonos API and playground, achieving impressive time-to-first-audio (TTFA) metrics. The hybrid model demonstrates particularly efficient performance characteristics, with reduced latency and memory overhead compared to its transformer counterpart, thanks to its Mamba2-based architecture that relies less heavily on attention blocks.
Training and Architecture Details
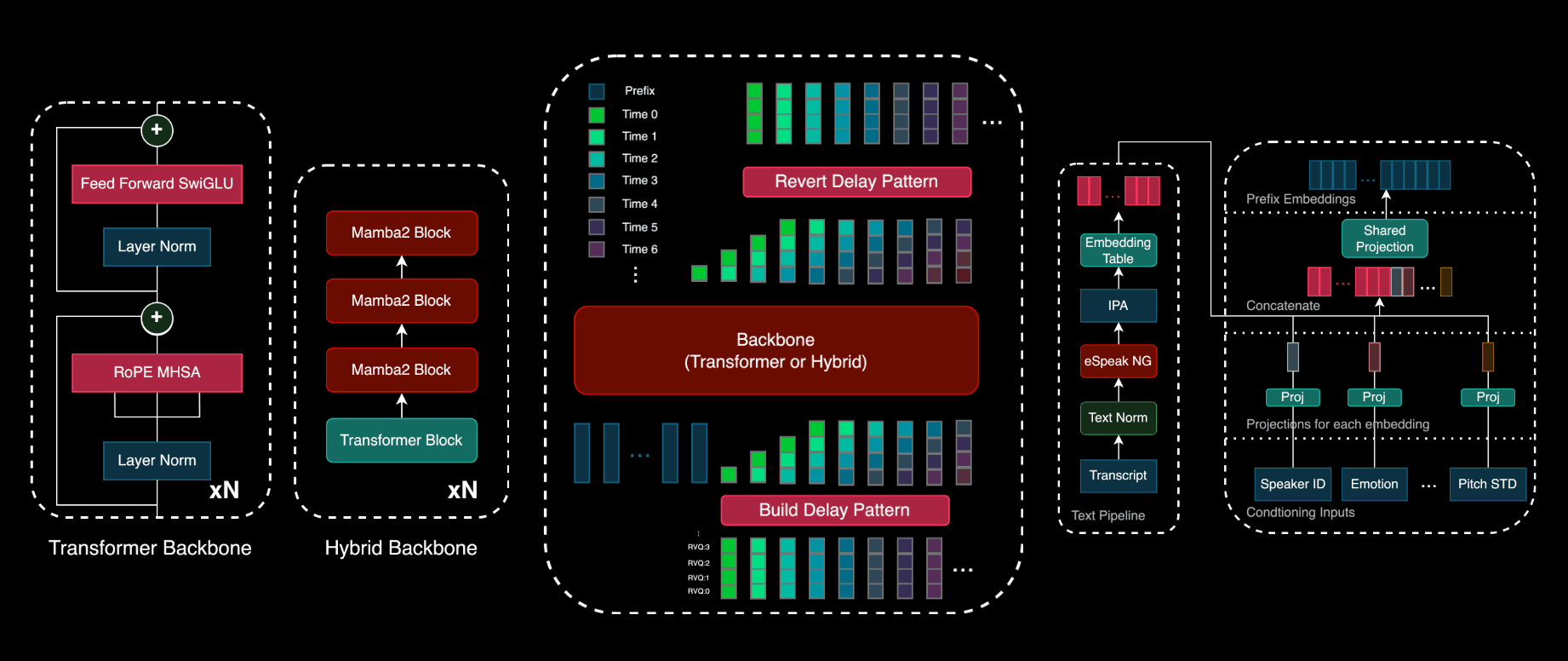
The Zonos-v0.1 models are trained on a simple autoregression task to predict a sequence of audio tokens given text and audio tokens. These audio tokens are computed from the raw speech waveform using the descript audio codec (DAC) autoencoder. DAC is a high-bitrate autoencoder which gives our model a high quality ceiling at the cost of a more challenging prediction problem and requiring a greater amount of tokens to be generated per second. To input the text to the model, we first normalize it and then obtain phonemes using the eSpeak phonemizer. Our transformer or hybrid model backbones then take these input phonemes and predict audio tokens as outputs. The model also receives a speaker embedding as input which gives it its voice cloning capabilities. To enable flexible control of the generated speech, Zonos-v0.1 models also receive a number of conditioning inputs such as speaking rate, pitch, sample rate, audio quality, and speaker emotions.
Zonos-v0.1 was trained in two phases. In phase 1, which lasted the longest, we pre-trained the models using only the text prefix and speaker embedding. This lasted approximately 70% of training. During the final 30% we added the conditioning inputs to the model and slightly upweighted higher-quality data. We found that this two-phase training improved model robustness and general quality.
While we believe our model has the highest quality ceiling of any publicly released model today, it also has several limitations. Our streamlined autoregression approach gives the model full flexibility of output however it also gives the model room to make many mistakes. During testing we observed a higher concentration of audio artifacts at the beginning and end of generations compared to proprietary models. Common artifacts include coughing, clicking, laughing, squeaks, and heavy breathing. Additionally, due to our unstructured autoregression approach, our model can sometimes make mistakes in text alignment and either skip over or repeat certain words, especially in out-of-distribution sentences.
Our high bit-rate autoencoder maximizes quality, but comes at a cost of slower and more expensive inference. To generate a second of audio, our model must generate 86 frames across 9 codebooks, meaning we must generate 774 tokens to produce a second of audio! We utilize the delay codebook pattern from Parler TTS, multi-token prediction, and embedding merging, to keep generation speed manageable and extend context. During the token embedding phase, we embed and merge groups of 9 tokens (corresponding to DAC’s codebook size) into a single embedding before sending it through the transformer and hybrid models. After the last layer we use 9 separate language modeling heads to predict 9 tokens from each embedding. This significantly improves performance at minimal generation quality cost. In practice, we find that our model is able to achieve an acceptable latency of 200-300ms and a real-time-factor (length of audio generated divided by time taken to generate it) significantly above 1 on an RTX 4090. However, there are many improvements that can be made to further improve latency.
In future model releases, we aim to significantly improve the model's reliability, its ability to handle specific pronunciations, the number of supported languages, and the level of control over emotions and other vocal characteristics afforded to the user. We will also pursue further architectural innovations to boost model quality and inference performance.